本文记录 sklearn 入门练习:使用机器学习算法处理乳腺癌检测问题。根据患者的细胞特征数据,建立模型来判断肿瘤性质(良性或恶性)。
数据的载入与预处理
使用经典的威斯康星州乳腺癌数据集,包含结块厚度、细胞大小、形状均匀性、边缘黏附力等特征。
对数据进行预处理后,输入到机器学习模型进行训练和预测。
import numpy as np
import pandas as pd
from pandas.plotting import scatter_matrix
import matplotlib.pyplot as plt
# 案例使用 Python2 和 0.19.1 的 sklearn,如今在 API 的调用上已经有许多不同之处
# from sklearn import preprocessing, cross_validation
# 更新
from sklearn import preprocessing, model_selection
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
# 载入数据集
names = ['id', 'clump_thickness', 'uniform_cell_size', 'uniform_cell_shape',
'marginal_adhesion', 'single_epithelial_size', 'bare_nuclei',
'bland_chromatin', 'normal_nucleoli', 'mitoses', 'class']
df = pd.read_csv('data.csv', names=names)
数据预处理不复杂,主要就是清洗和划分数据集。
# 数据清洗
## 替换缺失数据
df.replace('?',-99999, inplace=True)
## 删除无关特征
df.drop(['id'], axis=1, inplace=True)
## 检查数据
print(df.loc[10])
## 查看维度
print(df.shape)
# 描述性统计
print(df.describe())
输出:
clump_thickness 1
uniform_cell_size 1
uniform_cell_shape 1
marginal_adhesion 1
single_epithelial_size 1
bare_nuclei 1
bland_chromatin 3
normal_nucleoli 1
mitoses 1
class 2
Name: 10, dtype: object
(699, 10)
clump_thickness uniform_cell_size uniform_cell_shape \
count 699.000000 699.000000 699.000000
mean 4.417740 3.134478 3.207439
std 2.815741 3.051459 2.971913
min 1.000000 1.000000 1.000000
25% 2.000000 1.000000 1.000000
50% 4.000000 1.000000 1.000000
75% 6.000000 5.000000 5.000000
max 10.000000 10.000000 10.000000
marginal_adhesion single_epithelial_size bland_chromatin \
count 699.000000 699.000000 699.000000
mean 2.806867 3.216023 3.437768
std 2.855379 2.214300 2.438364
min 1.000000 1.000000 1.000000
25% 1.000000 2.000000 2.000000
50% 1.000000 2.000000 3.000000
75% 4.000000 4.000000 5.000000
max 10.000000 10.000000 10.000000
normal_nucleoli mitoses class
count 699.000000 699.000000 699.000000
mean 2.866953 1.589413 2.689557
std 3.053634 1.715078 0.951273
min 1.000000 1.000000 2.000000
25% 1.000000 1.000000 2.000000
50% 1.000000 1.000000 2.000000
75% 4.000000 1.000000 4.000000
max 10.000000 10.000000 4.000000
接下来,通过直方图和散点图对数据进行可视化。
scatter_matrix(df, figsize = (18,18))
plt.show()
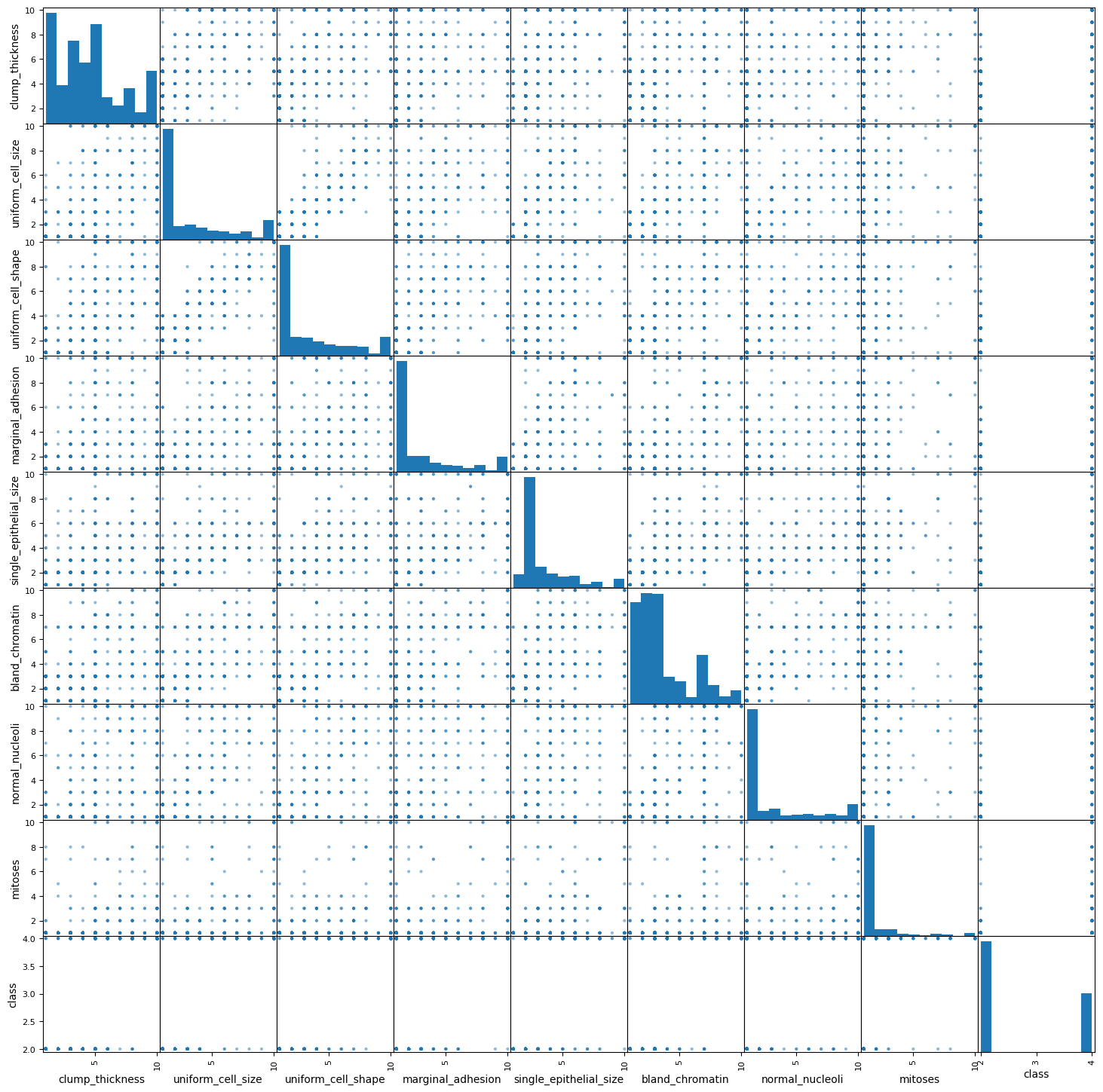
从图中可以更直观地观察数据分布及特征变量之间的关系,便于选择合适的机器学习算法。
sklearn 提供了划分数据集的 API(注意 train_test_split 现已移至 model_selection 模块)。
X = np.array(df.drop(['class'], 1))
y = np.array(df['class'])
# sklearn 0.19.1
# X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=0.2)
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.2)
模型训练
作为入门练习,使用 SVM 和 KNN 两种经典算法建模,并进行比较分析。
- SVM:通过构建高维空间中的最优超平面,将数据分为不同类别
- KNN:计算测试样本与训练样本之间的距离,选取最近的 K 个邻居,按类别投票决定分类结果
seed = 8
scoring = 'accuracy'
# 定义模型
models = []
models.append(('KNN', KNeighborsClassifier(n_neighbors = 5)))
# scikit-learn 在 0.22 版本中对 SVC 的默认参数进行了更改
# gamma 参数的默认值从 'auto' 改为 'scale'
# models.append(('SVM', SVC()))
models.append(('SVM', SVC(gamma='auto')))
# 记录模型表现
results = []
names = []
for name, model in models:
# kfold = model_selection.KFold(n_splits=10, random_state = seed)
# 指定 seed 需要令参数 shuffle = True
kfold = model_selection.KFold(n_splits=10, shuffle = True, random_state = seed)
cv_results = model_selection.cross_val_score(model, X_train, y_train, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
使用 10 折交叉验证评估模型:将训练数据随机分为 10 等分,模型重复训练 10 次,每次选择 1 折作为测试集,其余 9 折作为训练集,最终以 10 次验证结果的准确率评估模型表现。结果如下:
KNN: 0.966039 (0.029270)
SVM: 0.960649 (0.032726)
模型应用
使用事先划分好的非训练数据进行验证:
for name, model in models:
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(name)
print(accuracy_score(y_test, predictions))
print(classification_report(y_test, predictions))
输出结果如下:
KNN
0.9785714285714285
precision recall f1-score support
2 0.99 0.98 0.98 95
4 0.96 0.98 0.97 45
accuracy 0.98 140
macro avg 0.97 0.98 0.98 140
weighted avg 0.98 0.98 0.98 140
SVM
0.9642857142857143
precision recall f1-score support
2 1.00 0.95 0.97 95
4 0.90 1.00 0.95 45
accuracy 0.96 140
macro avg 0.95 0.97 0.96 140
weighted avg 0.97 0.96 0.96 140
classification_report 评估报告包含每个类别的主要评价指标:
- Precision(精确率):表示模型预测为某类别的样本中,有多少比例是真正属于该类别的。适合关注减少误报的场景(如癌症诊断中避免误诊为癌症)
- Recall(召回率/灵敏度):表示真实属于某类别的样本中,有多少被模型正确识别。高召回率意味着模型能捕获更多正样本,适合关注减少漏报的场景(如癌症筛查中尽量避免漏诊)
- F1-Score(F1值):Precision 和 Recall 的调和平均值,用于权衡二者
以 SVM 的报告结果为例:
- Class 2(良性):
- Precision = 1:模型预测为 Class 2 的样本中,100% 是真正的 Class 2
- Recall = 0.95:真实为 Class 2 的样本中,95% 被正确预测为 Class 2
- F1-Score = 0.95:综合 Precision 和 Recall 的平衡值
- Support = 95:测试集中有 95 个真实的 Class 2 样本
- Class 4(恶性):
- Precision = 0.90:模型预测为 Class 4 的样本中,90% 是真正的 Class 4
- Recall = 1:真实为 Class 4 的样本中,100% 被正确预测为 Class 4
- F1-Score = 0.95:综合 Precision 和 Recall 的平衡值
- Support = 45:测试集中有 45 个真实的 Class 4 样本
总体指标:
- accuracy:模型正确预测的样本比例为 96%
- macro avg(宏平均):对所有类别的指标求简单平均,不考虑每个类别样本数的不同
- weighted avg(加权平均):对所有类别的指标加权平均,权重为各类别的样本数